
Haben Sie hin & wieder mit in Fraktur gesetzten Texten zu tun? Wollen Sie aus einem solchen zitieren oder das Teil einfach durchsuchbar machen? Vielleicht wollen Sie so eine alte Schwarte in Ihrem feschen e‑Book-Reader lesbar in den Urlaub mitnehmen. Ich zeige Ihnen rasch, wie das geht, ohne dass Sie die happigen Preise für die Fraktur-Optionen der großen OCR-Programme berappen müssen. In maximal fünfzehn Minuten – nach Überfliegen des Artikels – können Sie loslegen.

Ich hatte die OCR-Software »Tesseract« im Zusammenhang mit der Erkennung der guten alten Fraktur schon mal im Blog vorgestellt. Aber das ist eine Weile her. Die ganze Geschichte ist denn auch – zwei, drei Software-Versionen später – herzlich veraltet. Da jedoch immer noch täglich Interessierte auf der alten Seite landen und eine ganze Reihe einschlägiger E‑Mails mit Anfragen eingetrudelt sind, habe ich mich noch mal hingesetzt und geguckt, was sich in Sachen Fraktur-OCR getan hat.
Das Problem mit der phantastischen und – nebenbei bemerkt – kostenlosen & freien OCR-Software »Tesseract« ist, jedenfalls für uns Windows-Nutzer, dass das UNIX-Programm über keine nutzerfreundliche GUI (graphische Benutzeroberfläche), auch Frontend genannt, verfügt, sondern über Kommandozeilen bedient werden muss. Für Linux-User ein Klacks …

Wir brauchen also zweierlei:
Ein Windows-Frontend für die neueste Version von »Tesseract«
(das ist die 5.0)
sowie ordentlich »trainierte« Erkennungsdateien,
in unserem Fall für die Fraktur.
Keine Bange: Ich habe Ersatz für besagte veraltete graphische Benutzeroberfläche aufgetan. Mein alter Vorschlag war ohnehin etwas primitiv; es gibt mittlerweile weitere – und die, die ich Ihnen hier vorstellen möchte, ist auch von der Optik her weitaus flotter. Gucken Sie mal:
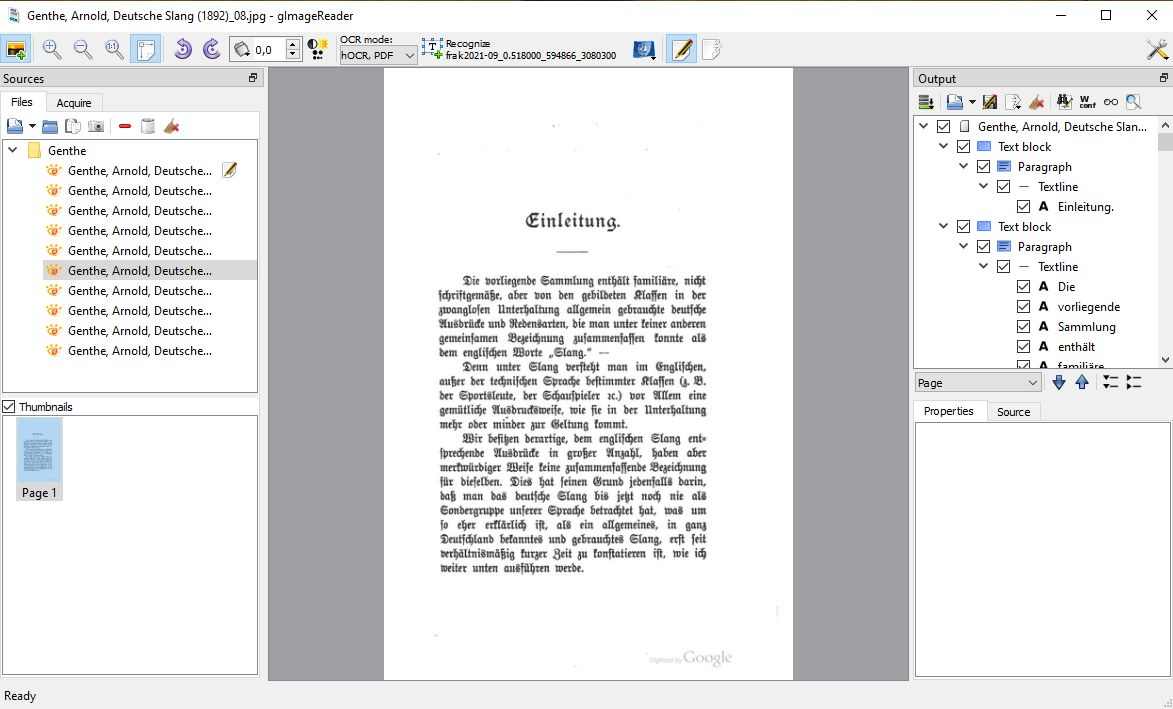
Dieses doch recht ansehnliche Frontend für unsere Tesseract-OCR-Dateien nennt sich »gImageReader«, und wir ziehen uns das Teil gleich mal als erstes hier. Scrollen Sie zum Download etwas runter. Ich habe mir die Datei »gImageReader_3.4.0_qt5_x86_64.exe« gezogen und installiert. Kann sein, dass Ihre Firewall mault & das unter Quarantäne stellt, aber da gehen Sie eben vor wie sonst auch in solchen Fällen. Wie auch immer, diese GUI unterstützt nun auch die OCR-Dateien für »Tesseract 5.0«, das ja erst Ende November ’21 fertig wurde. Also ganz frisch. Merken Sie sich bitte, wohin Sie die Software installieren, da wir dort auch gleich noch die eigentlichen OCR-Dateien reinschieben müssen. Dass Ihr PC für diese nietnagelneue Software auf dem neuesten Stand sein sollte, versteht sich von selbst …

Jetzt zu den eigentlichen Tesseract-Dateien: Da hat sich in Sachen Fraktur die Universität Mannheim verdient gemacht. Dort liest man damit seinen Schatz an alten deutschen Zeitungen ein. Und vor allem trainiert man die Erkennungsdateien fleißig weiter. Wir benutzen also nicht die Standard-Tesseract-Dateien, sondern die von der Uni Mannheim »trainierten«. Deshalb haben diese auch die Datei-Endung *.traineddata.
Die Suche nach dem, was wir brauchen, gestaltet sich kompliziert, weil man sich da doch irgendwie durchackern muss, aber da ich das schon erledigt habe, ziehen Sie sich einfach mal die derzeit aktuelle Datei, die laut Website der Uni derzeit die besten Ergebnisse erzielt: frak2021‑0.905.traineddata. Lassen Sie sich nicht erst groß verwirren. In dem von mir eingelesenen Beispielbuch (Arnold Genthe, Deutsches Slang) brachte diese auch die besten Ergebnisse. Wenn ich schon mal vorausschicken darf, dass ich begeistert war. Kein Vergleich zu meinen Versuchen vor einigen Jahren!

Jetzt müssen wir diese Datei noch in das Programmverzeichnis schieben, damit gImageReader sie auch findet. Falls Sie bei der Installation kein anderes Zielverzeichnis angegeben haben, ist folgendes das richtige Zuhause dafür: …\gImageReader\share\tessdata. Ihr PC wird Sie bitten, das in der dazu benötigten Eigenschaft des Administrators zu tun, falls es Ihnen auch als solcher nicht gelingen sollte, geben Sie in den Einstellungen des gImageReader (das gekreuzte Werkzeug rechts oben) unter »Preferences>Language language definitions path« Ihren Wunschpfad ein und schieben sie die OCR-Datei[en] dort rein.

Wo Sie schon im Installations-Verzeichnis von gImageReader sind, gehen Sie doch gleich noch in das Unter-Verzeichnis …\gImageReader\bin und sorgen Sie für eine flotte Verknüpfung der Datei »gimagereader-qt5.exe« mit Ihrem Desktop. Die Installationsroutine scheint eine solche Option nicht anzubieten …

Wenn Sie den gImageReader geöffnet haben, sehen Sie in der Mitte oben die jeweils aktive OCR-Datei, augenblicklich das Englische, da die Software sonst keine mitliefert. Es gibt sie jedoch definitiv für jede Sprache, die Ihnen nur einfallen möchte, aber davon später … Klicken Sie nun rechts daneben auf die blaue Flagge. Falls hier nur Englisch angezeigt wird, gehen Sie noch mal zu den Werkzeugen und klicken bitte »Redetect Languages«, dann sollte die Fraktur-OCR auftauchen. Damit sind Sie bereit für die Datei-Eingabe …

Ich möchte hier nicht zu sehr ins Detail gehen, weil alles Übrige wie üblich mit etwas Geduld durch Anklicken aller Optionen rauszufinden ist. Will auch niemanden bevormunden. Aber für einige erste Schritte bin ich eigentlich selbst auch immer recht dankbar. Also:
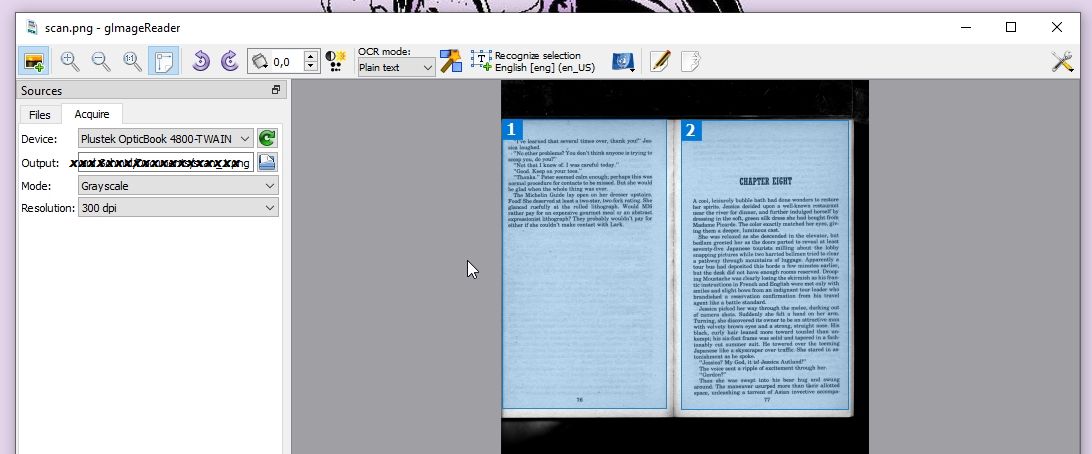
- Sie können sich an einem Direkt-Scan versuchen. Dazu in der linken Spalte (die Sie übrigens mittels des bunten Bildchens in der linken oberen Ecke ein- und ausblenden können) auf »Acquire« gehen. Dort dürfte dann auch schon Ihr Scanner angezeigt sein. Falls auf einen Klick auf »Scan« hin Ihre Twain-Schnittstelle aufgeht, Glück gehabt! Falls nicht dürfte das eine der Zeitsenken werden, die ich mir mittlerweile erst gar nicht mehr antue.
- In letzterem Fall scannen Sie lieber mit Ihrer üblichen Scan-Software und füttern iImageReader mit fertigen Bildern. Das geht nämlich nun wirklich geschmeidig. Dazu gehen Sie bitte in der linken Spalte auf »Files« und hangeln sich bis zu Ihrem Bildverzeichnis durch. Oder Sie schieben ihre jpgs oder was auch immer aus dem Bildverzeichnis per Drag & Drop ins obere Feld. Das ist wirklich eine feine Sache.
- Sie können die zu scannenden Bereiche bzw. den betreffenden Text dann markieren. Um nur ein Beispiel zu zeigen. Im folgenden Screen-Shot habe ich bei gedrückter Strg/Ctrl-Taste zwei Rahmen gezogen, und fertig war die Laube:

Zur eigentlichen Texterkennung brauchen Sie jetzt nur noch in der Mitte oben auf die Sprache zu drücken. Vorher können Sie noch links daneben unter »Scan Mode« zwischen »Plain Text« und »hOCR/PDF« wählen. Das müssen Sie einfach ausprobieren. Dasselbe gilt für die Entscheidungen, wie das Programm die Seite interpretieren soll. Dazu die blaue Flagge und dann »Page Segmentation Mode« … Wie auch immer: Bitte nicht mich fragen.
Wie Sie sehen, können Sie am grünen Schnarchbalken unten rechts den Fortschritt der Prozedur mitverfolgen. Die Geschichte geht selbst bei zig Seiten ziemlich flott. Es erscheint dann rechts eine dritte Spalte, die Sie nicht weiter verwirren soll. Sie können bei Gelegenheit mal in Ruhe ausklamüsern, was das alles soll. Wenn Sie etwa die Häkchen von bestimmen Absätzen wegmachen, werden diese beim Export ausgelassen.
Die verschiedenen Scan-Modi bedingen unterschiedliche Exportmöglichkeiten. Fangen Sie einfach mal mit »Plain Text« an. Speichern Sie das ganze in der rechten Spalte durch einen Klick auf das zweite Icon von links unter einer *.txt-Datei. Dann haben Sie schon mal was. Die können Sie dann in Word oder im Writer von Open/Libre Office weiterbearbeiten.

Wenn Sie weitere Erkennungssprachen benutzen wollen, es gibt sie wie gesagt alle, dann schauen Sie mal hier. Suchen Sie sich aus, was Sie brauchen, klicken Sie drauf und dann im nächsten Fenster rechts auf Download. Mit den Dateien verfahren Sie bitte wie gehabt: einfach ins jeweilige tessdata-Unterverzeichnis des Installationsordners verschieben. Dann die Sprachenliste auffrischen. Siehe oben.
Das wär’s erst mal. Dieses Frontend ist ein bisschen komplizierter als der Vorschlag vor einigen Jahren, aber dafür lässt sich auch mehr mit machen. Das Thema lässt sich bei Gelegenheit sicher noch etwas ausführen. Aber für’s Erste dürfte es wohl genügen. Probieren Sie’s einfach mal aus … Und hinterlassen Sie ruhig einen Kommentar, statt e‑Mails zu schicken, da haben dann alle was von. Fragen beantworte ich gerne, so weit ich bereits Bescheid weiß, ich kann nur darüber hinaus keine Zeit investieren …





Erste Nachträge
Die Dateien für Rechtschreibung & die Prüfung selbiger. Mein zweites Anliegen neben der Fraktur war eine OCR-Software für das Russische. Entsprechend habe ich das auch gleich ausprobiert. Da kam jedoch die Meldung, die »spell check«- & »dictionary-Dateien« seien nicht installiert. Die angebotene automatische Installation wollte jedoch nicht, wie sie sollte. (Vermutlich irgendwelcher Zugriffsrechte auf die Systemplatte wegen.) So habe ich mich auf die Suche gemacht & bin fündig geworden. Unser gImageReader arbeitet mit den Spellcheck-Dateien von Open/Libre-Office. Die gibt es hier. Suchen Sie einfach das logische Kürzel für die von Ihnen gewünschte Sprache, klicken den entsprechenden blauen (!) Link an und ziehen sich auf der folgenden Seite per Rechtsklick (Ziel speichern unter) zwei Dateien mit der Endung *.aff respektive *.dic. In meinem Fall also »ru_Ru.aff« & »ru_Ru.dic«. Diese schieben Sie dann bitte in das uns bereits bekannte Installationsverzeichnis, genauer gesagt in das Unterverzeichnis »gImageReader\share\myspell«. Ich habe rasch einen Screen-Shot von einer russischen Website gemacht & eingelesen. Tadellos!
Was die recht ordentlichen Resultate der Fraktur-Erkennung anbelangt, gilt, was ich schon in meinem alten Artikel dazu gesagt habe: Die Fehler, die ausgegeben werden, tauchen in der Regel öfter auf & lassen sich in der Textverarbeitung mittels »Alles ersetzen« größtenteils mühelos tilgen. Hier empfehle ich allen, sich ein Makro zu schreiben, das alle Fehler auf einen Streich abarbeitet. Wenn man das pflegt, bekommt man nach ein paar Nachbesserungen des Makros bereits mehr als anständige Dateien. Versuchen Sie einfach, so viele Regelmäßigkeiten zu erkennen wie irgend möglich und notieren sich diese in ein gutes altes Schulheft …
Um nur ein Beispiel für das Erste zu nennen, was man diesbezüglich machen kann: das »lange s« (»ſ« Unicode U+017f), das bei der Fraktur einem »f« ohne Strichlein in der Mitte gleicht, in ein »s« umwandeln. Sozusagen der erste Schritt des Makros. Da sieht der Text gleich ganz anders aus …
Ich habe ein bisschen mit verschiedenen Kombinationen & Erkennungsdateien experimentiert, um zu sehen, was da rauszuholen ist. Und ich denk mal, da kann man nicht maulen. Da der Begriff Fraktur im weiteren wie im engeren Sinne unterschiedliche Fonts bezeichnet, sollte man vielleicht alle verfügbaren ausprobieren. (Es gibt übrigens auch eine speziell mit österreichischen Zeitungen trainierte Erkennungsdatei). Ich zeige Ihnen hier mal ein Ergebnis mit folgender Kombi:
- die Erkennungsdatei mit dem Namen »frak2021‑0.905.traineddata«. (Klicken Sie, der Link führt Sie direkt ins Repositorium der Uni Mannhein (Danke, Leute!). Laden Sie die Datei & verfahren damit wie oben beschrieben. Diese Datei ist dann im gImageReader anzuwählen.
- der Scan-Modus war »hOCR/pdf«
- unter »Page Segmentation Mode« war »Assume single column of text« angeklickt
- exportiert habe ich unter »Output« (rechte Spalte) mit »save as hOCR text«; das gibt ein html-Dokument. (Da lässt sich der Text schön markieren & zur weiteren Verarbeitung kopieren.) Html empfand ich bisher als die einfachste & schnellste Lösung.
- das erste Dokument ist unbearbeitet; für das zweite habe ich die im gImageReader eingebaute »Find and Replace«-Funktion benutzt. (Das ist der Feldstecher in der Output-Spalte.) Hier habe ich ins obere Feld ein »langes s« reinkopiert (habe ich aus einer anderen Datei kopiert) und ins zweite unser heutiges »s«; dann »replace all« gedrückt und siehe da …



Die Version mit dem modernen »s« sieht nun wirklich verdammt gut aus & lässt sich in jeder Textverarbeitung recht flott durchkorrigieren; das ist das beste Resultat, das ich je bekommen habe.
Das Ersetzen von bestimmten Zeichen im gImageReader selbst: Nach erfolgtem Scan erscheint – wie oben erwähnt – rechts eine dritte Spalte mit dem Titel »Output«. Klicken Sie bitte dort auf den Feldstecher; damit öffnen Sie die Option »Find and Replace«. Hier klicken Sie am besten gleich mal »Match case«; damit sagen Sie dem Prozess, dass er Klein- und Großschreibung beachten soll.
Was sich her definitiv anbietet ist, das »lange s« in unser heutiges »s« umzuwandeln. Das »lange s« erzeugt man mittels eines Unicode-, tja, Codes: »U+017f«. Das geht jedoch nur in einer Textverarbeitung, also etwa in Word oder dem (längst besseren) Writer von Libre/Open-Office. Sie tippen den Code ein und drücken dann, ohne ein Leerzeichen zu setzen (!), die Tastenkombination »Alt+c«. Dann sollte das »ſ« erscheinen. Das lässt sich dann in das Feld »Find« kopieren. Um den Buchstaben dann im ganzen Text zu ersetzen, drücken Sie einfach auf den zweiten Feldstecher rechts neben dem Feld »Replace«. Mittels des ersten kann man sich wohl einzelnen durchhangeln; das habe ich aber noch nicht ausprobiert.
Das Ersetzen in gImage reader führt nicht etwa zu neuen Fehlern dort, wo die Software ein »s« statt eines »f« gelesen hat, sondern man sieht diese nur deutlicher. (Was durchaus ein Vorteil bei der Nachkorrektur in der Textverarbeitung ist.) Außerdem sehe ich in meinem Beispieltext, dass ein »p« gern mal zu »y« wird. Das muss man für sich selbst austarieren, was einem da lieber ist. So oder so, das Ergebnis ist besser als alles, was ich früher geschafft habe.
Dieser Beitrag hat 8 Kommentare
Hallo! Vielen Dank für die Benachrichtigung!!! Super Hilfestellung! Es ist möglich, das ich die neuen Datei in Ihre alte Version der Benutzeroberfläche getan habe. Mein englisch ist nicht so gut. Man man tut sich da schwer wenn so viel Text auf den Seiten ist. das mit dem ERsetzen von dem langen s verstehe ich noch nicht ganz. Darf ich noch fragen, wie geht das mit dem U+017f? Wenn es nicht zu viel Mühe macht? Vorab schon mal Dank!
Das mit dem »U+« funktioniert wohl nur in einer Textverarbeitung: Also »U+017f« in Word oder im Writer eingeben & dann OHNE ABSTAND »Alt+c« drücken; dann sollte das »lange s« erscheinen. Vielleicht lässt es sich auch aus dem Wikipedia-Artikel (siehe Link) dazu kopieren. Aber am einfachsten ist es, wie ich gemerkt habe, den Scan rasch mal als html-Dokument zu exportieren & das »lange s« dann dort rauszunehmen.
Das Ersetzen in gImage reader führt selbstverständlich zu Fehlern dort, wo die Software ein »s« statt eines »f« gelesen hat. Und dann sollte man wohl »Match case« (= »Groß- und Kleinschreibung beachten«) anklicken, damit großgeschriebene Substantive auf »S« nicht plötzlich klein geschrieben werden. Außerdem sehe ich, dass ein »p« gern mal zu »y« wird. Das muss man für sich selbst austarieren, was einem da lieber ist. So oder so, die Seiten waren in der Textverarbeitung unter Scherzen und Lachen flugs durchkorrigiert.
Hallo. Also muss ich jetzt echt sagen, Dass mit der Mail hätte ich echt nicht erwartet. Das schreit förmlich nach einem Dankeschön. Ich hatte nähmlich total aufgegeben. Mir gehts da wie Gandalf: Englisch nicht gut genug für kilometerlange Seiten Manual. Und übrigens habe ich gar nicht gewusst, dasset das lange s am PC überhaupt gibt. DANK!
Moinmoin! Möchte mich dem Dank der Kollegen anschließen. Jetzt verstehe ich auch, dass Sie da wohl recht viele Mails hatten?! Asche auf mein Haupt! Deswegen doppelten Dank für die Nachricht!!!
Gut das ich nicht gemailt habe. Ich dachte nämlich die ganze Softwar nach der alten beschreibung is für Popo. Wäre doch sehr dreißt gewesen. Dafür jetzt Danke. Ich hoffe dass ich so jetzt endlich meine Altvorderen in den Computer werd bringen können. Gruß!
Firma dankt! Kann mich dem allgemeinen Dankeschor nur anschließen. Übrigens hätte ich nich tgedacht dass das so viele überhaupt interessiert. Sie scheinen da in eine richtige Lücke gestoßen zu sein. Noch mal danke für das Mail!
Auch von mir ein herzliches Danke. Und es funktioniert in der hier beschriebenen Weise. Die anderen Exportfunktionen scheinen eher noch in Arbeit. Super. Genau das was ich seit Jahren wollte.
Unglaublich. Das ist eine Anleitung, die auch ein Nicht-IT-Experte verstehen und anwenden kann. Das didaktische Talent finde ich bewundernswert und ebenso die Bereitschaft so etwas für Andere zu erstellen und zu veröffentlichen. Ein riesiges Dankeschön! Endlich Frakturschriften ordentlich erkennen ohne mühsame Windows-Befehlseingabe.